J. Imaging, Free Full-Text
Por um escritor misterioso
Descrição
Image relighting, which involves modifying the lighting conditions while preserving the visual content, is fundamental to computer vision. This study introduced a bi-modal lightweight deep learning model for depth-guided relighting. The model utilizes the Res2Net Squeezed block’s ability to capture long-range dependencies and to enhance feature representation for both the input image and its corresponding depth map. The proposed model adopts an encoder–decoder structure with Res2Net Squeezed blocks integrated at each stage of encoding and decoding. The model was trained and evaluated on the VIDIT dataset, which consists of 300 triplets of images. Each triplet contains the input image, its corresponding depth map, and the relit image under diverse lighting conditions, such as different illuminant angles and color temperatures. The enhanced feature representation and improved information flow within the Res2Net Squeezed blocks enable the model to handle complex lighting variations and generate realistic relit images. The experimental results demonstrated the proposed approach’s effectiveness in relighting accuracy, measured by metrics such as the PSNR, SSIM, and visual quality.

The boomerang's erratic flight: The mutability of ethnographic

Exploring the Landscape of Women in Higher Education
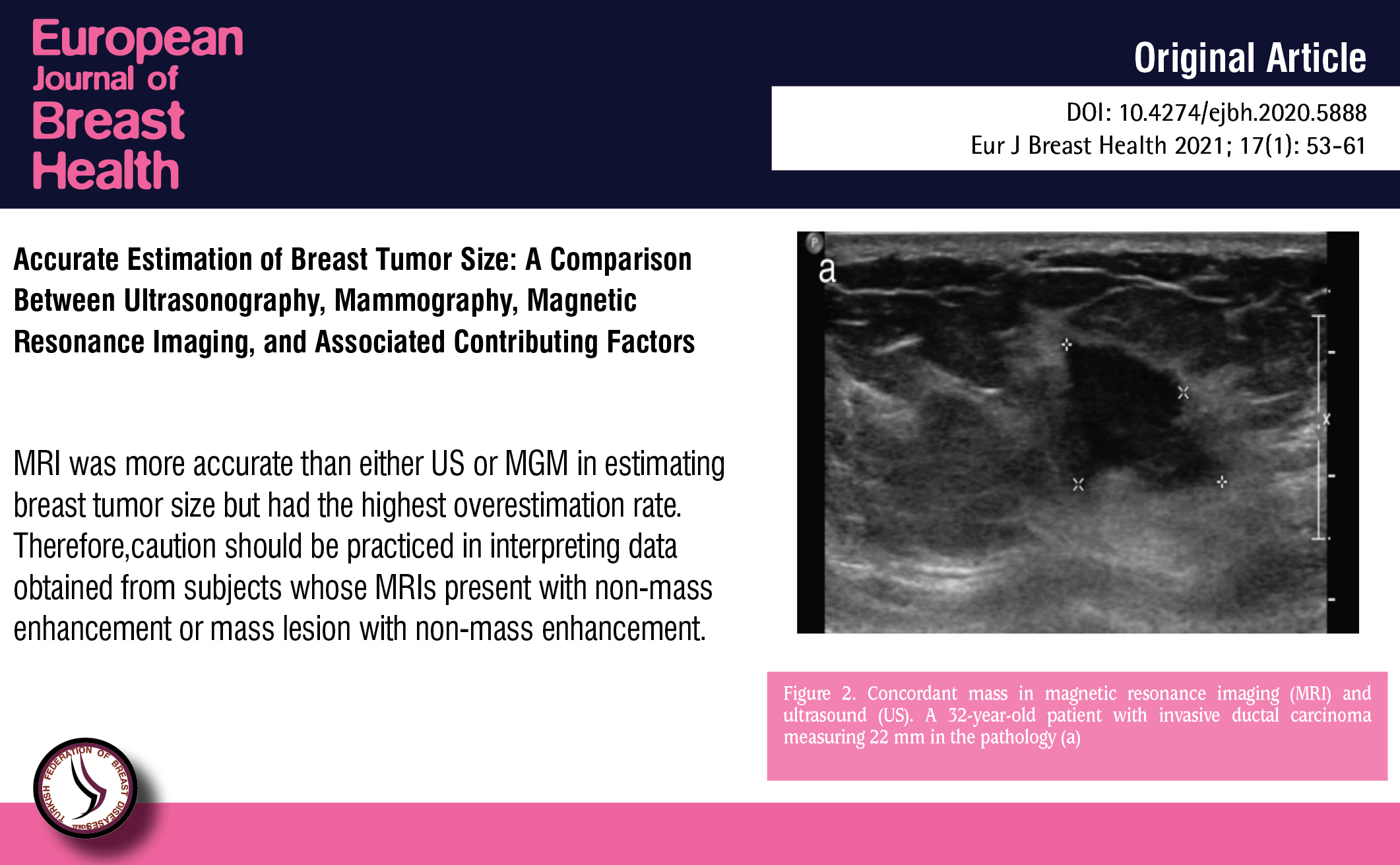
Eur J Breast Health on X: Accurate Estimation of Breast Tumor

Grand selection; The Beggar student [cornet, piano]

Genitourinary Imaging: Case Review, 3e by Kawamoto MD Satomi

Total-Body Positron Emission Tomography: Adding New Perspectives

Long-term results of high-density porous polyethylene implants in

In-Stent Neoatherosclerosis: A Cause of Late Stent Thrombosis in a
Fifty Reasons For Being A Homoeopath : J.ellis Barker : Free
Isolation and identification of a cDNA clone corresponding to an
de
por adulto (o preço varia de acordo com o tamanho do grupo)