Apresentamos a conversão de fala para texto, texto para fala e mais novidades para mais de 1.100 idiomas
Por um escritor misterioso
Descrição
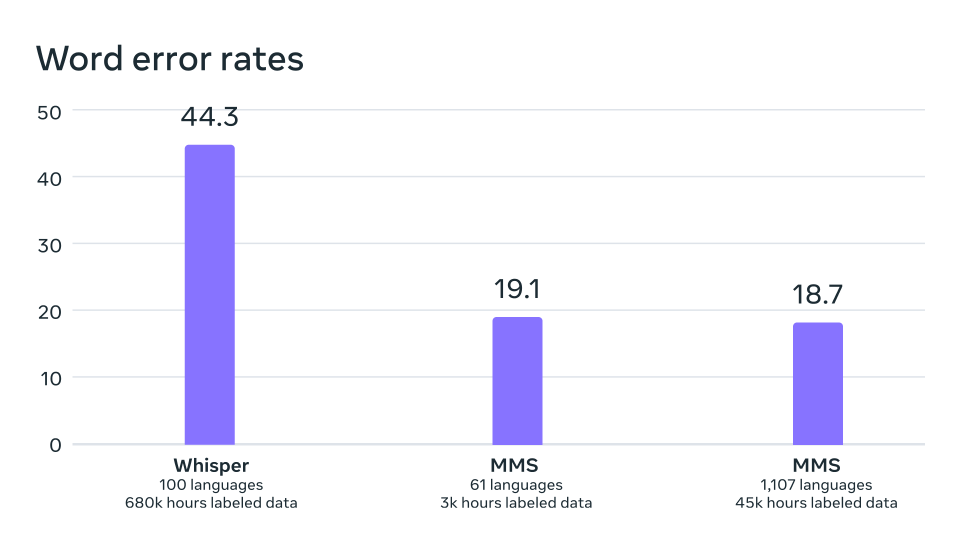
Expandimos a tecnologia de conversão de fala de cerca de 100 idiomas para mais de 1.000, criando um único modelo de reconhecimento de fala multilíngue que suporta mais de 1.100 idiomas (10 vezes mais do que antes), além de modelos de identificação de idiomas capazes de identificar 4.000 idiomas (40 vezes mais do que antes), e outros modelos pré-treinados que suportam 1.400 idiomas e modelos de conversão de texto em fala para mais de 1.100 idiomas. Nosso objetivo é facilitar o acesso das pessoas às informações e o uso de dispositivos no idioma de sua preferência. Equipar máquinas com a capacidade de entender e produzir falas, pode tornar as informações acessíveis para muito mais pessoas, incluindo aquelas que dependem inteiramente da voz para acessarem informações. No entanto, produzir modelos de aprendizado de máquina de boa qualidade para essas tarefas, requer grandes quantidades de dados rotulados – neste caso, milhares de horas de áudio, juntamente com transcrições – e para a maioria dos idiomas, esses dados simplesmente não existem. Por exemplo, os modelos de reconhecimento de fala existentes cobrem apenas cerca de 100 idiomas, uma fração dos mais de 7 mil idiomas conhecidos no planeta. Uma situação ainda mais preocupante é que quase metade desses idiomas correm o risco de desaparecer com o tempo. No projeto Massively Multilingual Speech (MMS), superamos alguns desses desafios ao combinar nossa técnica pioneira de aprendizado autossupervisionado, o wav2vec 2.0, com um novo conjunto de informações que fornece dados rotulados para mais de 1.100 idiomas e dados não rotulados para quase quatro mil idiomas. Alguns desses idiomas, como o Tatuyo, possui apenas algumas centenas de falantes e, na maioria deles, não há tecnologia de fala existente. Nossos resultados mostram que os modelos de Massively Multilingual Speech apresentam um bom desempenho quando comparados aos modelos existentes, e cobrem 10 vezes mais idiomas. A Meta tem foco na multilinguagem em geral: para texto, o projeto No Language Left Behind ampliou a tradução multilíngue para 200 idiomas, enquanto o projeto Massively Multilingual Speech ampliou a tecnologia de fala para muitos mais. Hoje, estamos compartilhando nossos modelos e código para que outros na comunidade de pesquisa possam criar a partir do nosso trabalho. Por meio desse projeto, esperamos fazer uma pequena contribuição para preservar a incrível diversidade linguística do mundo. Nossa abordagem O primeiro desafio foi coletar dados de áudio de milhares de idiomas, já que os maiores conjuntos de dados de fala existentes cobrem no máximo 100 idiomas. Para superar esse desafio, recorremos a textos religiosos, como a Bíblia, que foram traduzidos em diferentes idiomas e cujas traduções foram amplamente estudadas para pesquisas de tradução de idiomas baseadas em texto. Essas traduções, disponíveis publicamente, possuem gravações de áudio de pessoas lendo esses textos em diferentes idiomas. Como parte deste projeto, criamos um conjunto de dados de leituras do Novo Testamento em mais de 1.100 idiomas, que forneceu em média 32 horas de dados por idioma. Ao considerar gravações não rotuladas de várias outras leituras religiosas cristãs, aumentamos o número de idiomas disponíveis para mais de quatro mil. Embora esses dados sejam de um domínio específico e frequentemente lidos por falantes do gênero masculino, nossa análise mostra que nossos modelos apresentam um desempenho igualmente bom para vozes masculinas e femininas. E apesar de o conteúdo das gravações de áudio ser religioso, nossa análise mostra que isso não influencia o modelo a produzir uma linguagem mais religiosa. Acreditamos que isso se deve ao fato de usarmos uma abordagem de classificação temporal conexionista (CTC), que é muito mais restrita em comparação aos grandes modelos de linguagem (LLMs) ou modelos de sequência para sequência para reconhecimento de fala. Nós processamos previamente os dados para melhorar a qualidade e torná-los utilizáveis pelos nossos algoritmos de aprendizado de máquina. Para isso, treinamos um modelo de alinhamento em dados existentes em mais de 100 idiomas, que também foi utilizado juntamente com um algoritmo de alinhamento de força eficiente, no qual pode processar gravações longas de cerca de 20 minutos ou mais. Realizamos esse processo várias vezes e executamos uma etapa final de filtragem por validação cruzada com base na precisão do modelo para remover dados potencialmente desalinhados. Para permitir que outros pesquisadores criem novos conjuntos de dados de fala, adicionamos o algoritmo de alinhamento ao PyTorch e disponibilizamos o modelo de alinhamento. Trinta e duas horas de dados por idioma não são suficientes para treinar modelos convencionais de reconhecimento de fala supervisionados. Devido a isso, criamos o wav2vec 2.0, nosso trabalho anterior sobre aprendizado de representação de fala autossupervisionado, que reduziu consideravelmente a quantidade de dados rotulados necessários para treinar bons sistemas. De forma concreta, treinamos modelos autossupervisionados com cerca de 500 mil horas de dados de fala em mais de 1.400 idiomas — isso é quase três vezes mais idiomas do que qualquer trabalho anterior conhecido. Os modelos resultantes foram então ajustados para uma tarefa específica de fala, como reconhecimento de fala multilíngue ou identificação de idioma. Resultados Para entender melhor o desempenho dos modelos treinados nos dados de Massively Multilingual Speech, avaliamos esses modelos em conjuntos de dados de referência já existentes, como o FLEURS. Treinamos modelos de reconhecimento de fala multilíngues em mais de 1.100 idiomas usando um modelo wav2vec 2.0 de um bilhão de parâmetros. Conforme o número de idiomas aumenta, o desempenho diminui um pouco: a mudança de 61 para 1.107 idiomas aumenta a taxa de erro de caracteres em cerca de 0,4%, mas a cobertura de idiomas aumenta mais de 17 vezes. Em uma comparação direta com o Whisper da OpenAI, descobrimos que os modelos treinados nos dados de Massively Multilingual Speech alcançam metade da taxa de erro de palavras, mas cobrem 11 vezes mais idiomas. Isso demonstra que nosso modelo pode ter um desempenho muito bom em comparação aos melhores modelos de fala atuais. Em seguida, treinamos um modelo de identificação de idioma (LID) para mais de quatro mil idiomas usando nossos conjuntos de dados e conjuntos de dados existentes, como FLEURS e CommonVoice, e o avaliamos na tarefa de LID do FLEURS. Disponibilizar 40 vezes mais idiomas ainda resulta em um desempenho muito bom. Também criamos sistemas de texto para fala para mais de 1.100 idiomas. Os modelos atuais de texto para fala geralmente são treinados em corpora de fala que contêm um único locutor. Uma limitação dos dados de Massively Multilingual Speech é que, eles possuem relativamente poucos falantes diferentes para vários idiomas e, muitas vezes, apenas um único falante. No entanto, isso é uma vantagem para a criação de sistemas de texto para fala. Por isso, treinamos esses sistemas para mais de 1.100 idiomas. Constatamos que a fala produzida por esses sistemas é de boa qualidade, como mostram os exemplos abaixo. Estamos animados com nossos resultados, mas, como acontece com todas as novas tecnologias de IA, nossos modelos não são perfeitos. Por exemplo, existe certo risco de que o modelo de fala para texto possa transcrever incorretamente algumas palavras ou frases. Dependendo da transcrição gerada, isso pode resultar em linguagem ofensiva e/ou imprecisa. Continuamos acreditando que a colaboração na comunidade é fundamental para o desenvolvimento responsável das tecnologias de IA. Rumo a um único modelo de fala disponível para milhares de idiomas Muitos dos idiomas do mundo correm perigo de desaparecer, e as limitações das tecnologias atuais de reconhecimento e geração de fala só irão acelerar essa tendência. Visamos um mundo em que a tecnologia tenha o efeito oposto, incentivando as pessoas a manterem os idiomas vivos, pois podem acessar informações e usar a tecnologia falando em seu idioma preferido. O projeto Massively Multilingual Speech representa um avanço significativo nessa direção. No futuro, queremos aumentar a cobertura para disponibilizar ainda mais idiomas e também enfrentar o desafio de lidar com dialetos, o que geralmente é difícil para a tecnologia de fala existente. Nosso objetivo é facilitar o acesso das pessoas às informações e permitir que elas usem dispositivos em seu idioma preferido. Há muitos casos de uso concretos para a tecnologia de fala, como as tecnologias VR e AR, que podem ser usadas no idioma preferido de uma pessoa, bem como serviços de mensagens que podem entender a voz de todos. Também visamos um futuro em que um único modelo possa resolver diversas tarefas de fala para todos os idiomas. Embora tenhamos treinado modelos separados para reconhecimento de fala, síntese de fala e identificação de idioma, acreditamos que, no futuro, um único modelo será capaz de realizar todas essas tarefas e muito mais, levando a um melhor desempenho geral.

Caderno de Resumos do III Seminário de Estudos Linguísticos da

PDF) Ciencia Plurilingüe: Estrategias para el Futuro

estado_2011 by cea ong - Issuu

Marcelino Marques de Barros

Stephanie Teixeira Stacciarini no LinkedIn: #tánasuamão

PDF) (2021) Rodrigues-Moura, Enrique (ed.). Letras na América

Calaméo - A Universidade Da Palavra Dick Eastman

PDF) Semana de turismo on-line? Avaliação da experiência na
Apresentamos a conversão de fala para texto, texto para fala e
de
por adulto (o preço varia de acordo com o tamanho do grupo)







