Training AlphaZero for 700,000 steps. Elo ratings were computed
Por um escritor misterioso
Descrição
A summary of the DeepMind's general reinforcement learning algorithm, AlphaZero, by Umer Hasan

Generally capable agents emerge from open-ended play - Google DeepMind

A general reinforcement learning algorithm that masters chess, shogi, and Go through self-play

AI AlphaGo Zero started from scratch to become best at Chess, Go and Japanese Chess within hours

AlphaZero paper discussion (Mastering Go, Chess, and Shogi) • Life In 19x19
AlphaGo Zero Explained

AlphaZero paper peer-reviewed is available · Issue #2069 · leela-zero/leela-zero · GitHub

training - What does it mean for AlphaZero's network to be fully trained - Artificial Intelligence Stack Exchange
Checkmate for Traditional Chess? - Nekst-Online
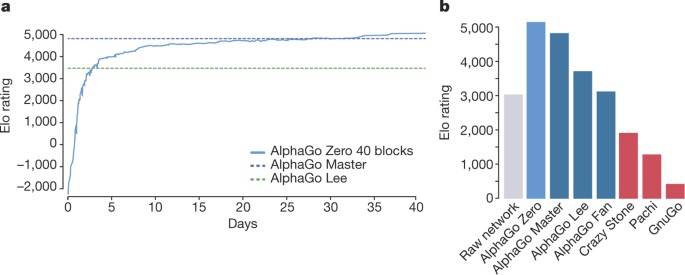
Mastering the game of Go without human knowledge
How many games did Alpha Zero played against itself during its four hours training? - Quora
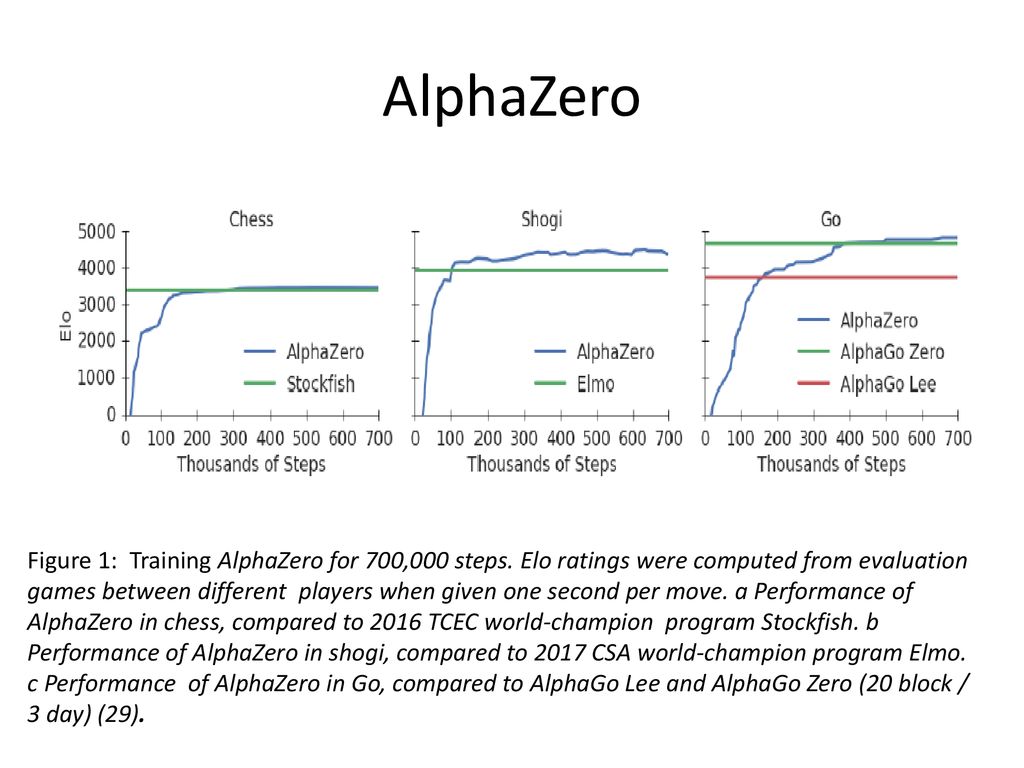
Function approximation - ppt download
de
por adulto (o preço varia de acordo com o tamanho do grupo)